
Impossible d’échapper au raz de marée IA, qui selon Henri Verdier sera la révolution numérique actuelle.
Et dans ce microcosme ou ChatGPt a distribué les cartes, tout le monde veux sa part du gâteau.
Apres Deepseek qui a prouvé qu’il existait des alternatives à Open AI, Mistral, L’IA Française vient également mettre son grain de sel avec son modele leger et performant.
pré-requis
alors pour plus de simplicité dans le prototypage, je suis partie sur?
Docker, comme d’hab
il nous faut donc
- une VM sur docker
- docker-compose
- un accès internet
Pourquoi utiliser Docker pour exécuter un modèle IA localement ?
L’utilisation de Docker présente plusieurs avantages :
- Isolation complète : Chaque conteneur fonctionne indépendamment, évitant les conflits de dépendances avec le système hôte.
- Déploiement rapide : Pas besoin d’installer manuellement les dépendances ou de configurer l’environnement, tout est encapsulé dans un conteneur.
- Portabilité : Que tu sois sur Linux, Windows ou macOS, exécuter Ollama avec Docker garantit un fonctionnement identique.
- Facilité de mise à jour : Mettre à jour Ollama ou tester différents modèles devient un jeu d’enfant en changeant simplement l’image Docker.
Cas d’usage possibles
L’association Mistral + Ollama en Docker ouvre de nombreuses possibilités :
- Chatbot local : Construire un assistant IA qui fonctionne en local, sans dépendre d’un cloud.
- Génération de texte hors ligne : Rédiger des articles, résumer des documents ou générer des scripts sans connexion Internet.
- Assistance au développement : Utiliser l’IA pour aider à la rédaction de code, commenter des scripts ou expliquer des concepts techniques.
- Automatisation et intégration : Connecter Mistral à d’autres services via une API locale, pour des workflows intelligents sans surcoût lié à l’IA en ligne.
Le docker-compose
Alors oui, j’ai pris l’habitude d’utiliser docker-compose et les fichiers yml pour mes projets docker, ça me parle plus que de lancer juste mes containers.
On va déjà crée la partie Ollama
Ollama !!!
ollama:
image: ollama/ollama:${OLLAMA_DOCKER_TAG-latest} # Image Docker Ollama
container_name: ollama # Nom du conteneur
restart: unless-stopped # Redémarrage automatique sauf arrêt manuel
ports:
- "11434:11434" # Expose le port 11434 pour les requêtes
tty: true # Active un terminal interactif
volumes:
- /ollama/modeles:/root/.ollama # Stockage persistant des modèles
extra_hosts:
- "host.docker.internal:host-gateway" # Permet au conteneur d'accéder à l'hôte
pull_policy: always # Télécharge toujours la dernière image si disponible
environment:
- OLLAMA_MODEL=mistral # Définit le modèle utilisé par OllamaLe fichier spécifie un volume monté sur /root/.ollama à partir du répertoire /ollama/modeles sur l’hôte. Cela permet de conserver les modèles téléchargés même après la suppression ou le redémarrage du conteneur.
Service Open-WebUI
Ce service fournit une interface web pour interagir avec Ollama. Il est basé sur l’image ghcr.io/open-webui/open-webui et est configuré comme suit :
open-webui:
image: ghcr.io/open-webui/open-webui:${WEBUI_DOCKER_TAG-main} # Image WebUI
container_name: open-webui # Nom du conteneur
restart: unless-stopped # Redémarrage automatique sauf arrêt manuel
ports:
- "3001:8080" # Expose le port 3001 pour l'interface web
environment:
- OLLAMA_BASE_URL=http://ollama:11434 # Connexion au service Ollama
- WEBUI_SECRET_KEY=your_secret_key # Clé secrète pour sécuriser l'accès (a modifier bien sur)
depends_on:
- ollama # Attente que le service Ollama soit démarré
volumes:
- open-webui:/app/backend/data # Stockage persistant des données
extra_hosts:
- "host.docker.internal:host-gateway" # Permet au conteneur d'accéder à l'hôteà l’issue il faudra récupérer le modèle de Mistral
docker compose exec ollama ollama pull mistralD’autres modèles?
Bien sur, chauvinisme oblige, j’ai commencé par utiliser Mistral. Mais cela fonctionne également avec d’autres modèles d’IA tel que deepseek, Llama3 ou gemma, d’ailleurs on va également faire tourner ça.
On va tester avec deepseek qui possede plusieurs version
une 7 milliards de parametres : 7b
1.5 et 14b
La commande suivante télécharge la version 7 milliards de paramètres du modèle DeepSeek-R1. Vous pouvez remplacer 7b par la taille de modèle souhaitée, comme 1.5b ou 14b.
root@Docker:/docker# docker compose exec ollama ollama pull deepseek-r1:7b
pulling manifest
pulling 96c415656d37... 6% ▕██████████ 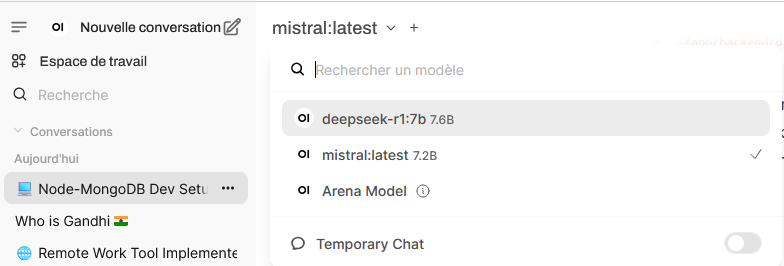
Vous pouvez voir qu’en plus de mes tests pour savoir qui est Gandhi, j’ai désormais deepseek et mistral côte à côte, je peux surfer de l’un à l’autre sans souci.
Conclusion
Utiliser Ollama avec Mistral en Docker est une excellente solution pour ceux qui recherchent à la fois performance, flexibilité et souveraineté sur leurs données. Contrairement aux services d’IA basés sur le cloud, qui imposent souvent des restrictions et des risques liés à la confidentialité, cette approche permet d’exécuter un modèle de langage puissant en local, sans envoyer de données à un serveur tiers.
Pourquoi c’est une bonne idée ?
- Souveraineté et confidentialité : Aucun envoi de données vers l’extérieur, ce qui est crucial pour des usages professionnels sensibles.
- Contrôle total : On peut choisir la version du modèle, ajuster les ressources allouées et même modifier Ollama selon ses besoins.
- Coût réduit : Pas d’abonnement ou de coûts cachés liés à une API cloud, une simple machine avec assez de puissance suffit.
- Performance locale : Pas de latence due à la connexion réseau, idéal pour une IA réactive et accessible immédiatement.
Quelles sont les limites ?
- Ressources matérielles : Un modèle comme Mistral, bien qu’optimisé, demande tout de même une machine avec un CPU puissant et, idéalement, une carte graphique pour accélérer l’inférence.
- Maintenance et mises à jour : Contrairement aux solutions cloud qui évoluent en arrière-plan, il faut gérer manuellement la mise à jour des conteneurs et des modèles.
- Évolution des modèles : De nouveaux modèles plus performants sortent régulièrement. Un usage local signifie qu’il faut surveiller ces évolutions et tester par soi-même les alternatives.
En conclusion, cette approche s’adresse à ceux qui veulent garder le contrôle sur leurs données, éviter les dépendances aux grandes plateformes et avoir une solution IA locale, efficace et économique. Un choix stratégique pour les entreprises, les développeurs et les passionnés de tech qui veulent une autonomie totale sur leur intelligence artificielle. 🚀